

「機能性表示食品」 機能性評価の実際② 臨床試験〝質〟への理解が大前提
2015年 1月29日 17:11
最近、よく耳にする「エビデンス(科学的根拠)」。そもそもエビデンスとは何か。これは「作る」「伝える」「使う」という3つの流れがある。
「作る」は自ら臨床試験を行うこと。新制度の「最終製品で行う臨床試験による実証」は、この「作る」で攻める手法になる。もう一つは、独自研究はないが、世界中の研究を集めてきて評価し「伝える」こと。「システマティックレビュー(SR)」で攻める手法になる。新制度において「使う」のは消費者が中心だ。ただ、SRも"質"の高い研究を集める必要がある。その"質"というものがよく分からない。
◇
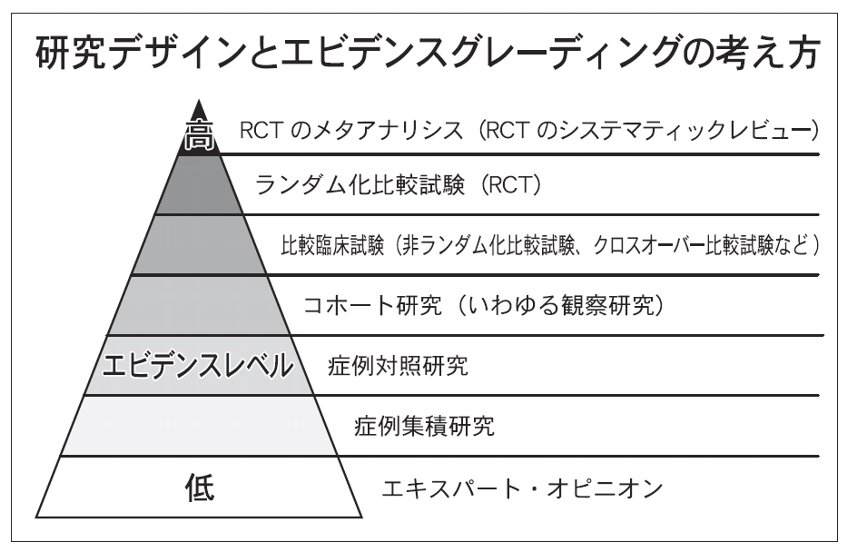
SRの"質"評価は、連載の中で後述するが、まず、その前提となる「臨床研究」の質から説明したい。試験には、「試験管内試験」や「動物試験」もあるが、新制度は「臨床研究」を前提としている。消費者目線に立てば、「関節の健康に」といった時に当然、人に対して効果があるものだと思うし、動物試験や試験管内試験の質や重みをどう評価すればよいか分からないからだ。ただ、臨床研究もピンキリだ。そのレベルを判断する「エビデンスグレーディング」を理解する必要がある。
◇
「わしは何年も臨床やってきたから、この見解は正しいんだ」「この成分は○○という疾病に効く」。健食の広告でたまにある手法。教授や医師の肩書を持った人物が顔写真入りで語っていたりするが、これは「エキスパートオピニオン」と呼ばれる。いわゆる"偉い人"の発言。少し前、ある薬事法違反事件に絡み成分の機能に関する原稿を執筆した教授が書類送検されたが、残念ながらレベルは一番下になる。
一方、最も真実性を示す可能性が高いとされるのが「ランダム化比較試験(RCT)」。「ランダム化」の由来は、人には"個人差"があるため。動物試験なら同じ遺伝子を持つネズミを2群に分ければいいが、遺伝子配列が異なる人の場合どうしようもない。そこで、その差を小さくするため、被験者を「摂取群」と「プラセボ群(偽薬群)」の2群にランダムに分ける。誤差を最小にできるため、研究実施者が被験者に干渉する「介入試験」で最も上のランクになる。
これに続き、被験者が「私は健食興味あるから飲みたい」、実施者が「あなたはこっち」などと割り付けるのが「非ランダム化比較試験」、同じ被験者が一定期間を置いて「摂取群」と「プラセボ群」を経験するのが「クロスオーバー比較試験」。前者は、被験者に偏りが生じるのが難点、後者は群間の差こそないものの、同じ被験者が2役をこなすため試験期間が長期に渡ることや、期間中に身体の状態が変化する可能性があること、また1期目の試験の影響を2期目に持ち越す可能性が問題とされる。
さらにレベルの低いものとして、「プラセボ群」など比較対照を作らず、摂取前後の状況を見る「前後比較試験」、摂取している人と年齢や性別が同じ摂取していない人を選び、違いから影響を探る「症例対照研究」、摂取している人の経過を集積してまとめる「症例集積研究」が続く。ここまでくると改善が摂取によるものかどうかも不透明で、分析的研究ではなくなる。
◇
「一番高いレベルを選べばよいのでは」と思うが研究コストの問題だけでなく、医薬品と異なる健食ならではの難しさもある。臭いや味、テクスチャーの問題だ。
例えば、青汁の場合、人口色素を使ったりさまざまな方法で「プラセボ」を作るが、本物と同じものは作りづらい。ニンニクも飲んだ後のげっぷなど服用感で違いが分かってしまったりする。このため、偽薬を提供するケースにわざと非常に薄めた臭いをつけたり、研究者の工夫が必要になる。場合によって「ランダム化―」ではなく「クロスオーバー」や「前後比較」でないと評価できないものもある。
ただ、重要なのは、これら研究で評価が違った場合、より上位の研究を採用する必要があることだ。
(③につづく、前回の①はこちら)



